

One of the main challenges faced when designing the COVID-X Sandbox has been efficiently integrating healthcare datasets from various sources, covering a wide range of healthcare aspects in clinical (e.g. EHRs, clinical trials) and non-clinical (e.g. laboratory studies) contexts. These datasets have been characterized by multiple types of heterogeneity and diversity regarding access restrictions and data description.
On the other hand, their contextualized use in diverse application domains (hospitalization, admission, transfer, diagnosis, therapy, monitoring activity, rehabilitation, monitoring signs and symptoms, statistics and reports, etc.) increased the challenge of their management and interoperable access. These data had to be efficiently curated, harmonized, annotated, and structurally and semantically enriched to be seamlessly accessible in an interoperable manner by third-party applications and services.

Thus, in the context of the COVID-X project, to allow for seamless access and use of disparate COVID19 relevant health, clinical and other data by innovative solution providers, further from providing the relevant distributed health data space, a major focus of work has been on the definition of a standards-compliant unified data model and light ontology, to be subsequently used by data ingestion services in annotating heterogeneous data in compliance to the COVID-X data model and thus allowing unified and seamless access to ingested data by data consumers/solution providers to use and validate their solution.
Further from the purpose of harmonized data access and management services provided by the COVID-X Sandbox, such data description harmonization processes using the data model have served in providing efficient and description-agnostic federated learning services, to serve for the cases that data could not be migrated to other data spaces, but rather their descriptions would.
The significance of the Data model in such processes has necessitated a thorough study and analysis of the available datasets from all Clinical partners, both Consortium partners (Humanitas, Sermas, Karolinska) but also Clinical partners having joined as part of funded teams through the two COVID-X Open calls, on the one hand, and the description needs and requirements of solution providers also joining through the two Open Calls of the project. Existing open data portals providing relevant data sets have also been analyzed and studied. In addition, existing standards and ontologies have been assessed to cover analyzed description needs and used (such as DCAT, HL7 FHIR, etc.). Relevant medical and other taxonomies have been used for determining standardized values for standard medical descriptors, such as the ICD-11 taxonomy.

In more detail, the characteristics of each dataset (including open ones) have been analyzed, including the data’s size, type, and format, as well as its variables and their values. Their structure and semantics have been extracted and mapped to identify relevant existing healthcare and other metadata standards and taxonomies. This further served the purpose of identifying gaps with respect to gathered description needs in the targeted diverse application domains, introducing the definition of the relevant descriptors, and formulating the COVID-X common semantic data model. A thorough process has been followed as shown in the diagram below.

The semantic data model provides a high-level structural and semantics-based representation of the data catalogue used to collect and store healthcare and other required data. The Sandbox primarily uses the semantic data model to facilitate data annotation, harmonization and cataloguing in a unified and common way for all types of aggregated heterogeneous datasets, targeting data interoperability in data access and use by consuming applications and users.
In COVID-X, we aimed to collect data from a multitude of third-party organizations, store them in a unified manner and make them seamlessly accessible in an interoperable manner to the corresponding third parties for further visualization, management and use.
COVID-X Unified Data Model Definition
In defining the COVID-X Data Model, a first step has been to create the upper-level classes of the data model hierarchy: Person → Patient, Disease, Task, Data, as shown below along with their relationships.

THE TOP LEVEL HIERARCHY OF THE UNIFIED DATA MODEL
The Person→Patient is infected by a Disease, which in our case is SARSCov2 (ICD-11 code: XN109SARSCov2). The Patient is described by (produces) a set of Data (collected datasets). Both the processing and analysis of collected Data and the detected Disease produce / cause a set of Tasks to be applied to the patient.
The Person entity represents the actors within the specific domain targeted by the system. It can be easily extended to include multiple variations of the Person entity (patient, clinician, etc.). It further includes all common features/attributes that these different variations/subclasses may have and inherit from the parent entity. Each single variation/.subclass may have its additional attributes/features for its complete description. A snapshot of the Person entity, Patient subclass is shown below.

The Disease entity is used to classify all diseases that can be a subject of a healthcare data system and follows the ICD-11 taxonomy, by linking this class to the one defined in ICD-11, as shown below. The mapping of the variables composing the COVID-X Unified Data Model to their ICD-11 codes is a crucial exemplary step towards achieving interoperability of the datasets included in the COVID-X Sandbox with other relevant datasets. Thereby, COVID-X makes an important step towards promoting the FAIR data principles using transforming the datasets included in the COVID-X Sandbox in a way to comply with them, considering existing standardized relevant efforts.

The Task entity defines a classification of the tasks executed by the Persons or Processes related to events such as disease outbreaks or impacts of events and response actions. It is structured in the following Subclasses: 1) Clinical (Diagnosis, Mechanical Ventilation & Therapy), 2) Administrative (Admission, Hospitalization & Transfer) and 3) Interview (Questionnaire & Chatbot). The 1st subclass refers to Clinical Tasks that involve the Patient in an active (Therapy that the Patient needs to have, the Patient is actively involved in e.g., taking his/her own medicine, etc.) or passive manner (Diagnosis that is made based on the Patient’s examinations). The 2nd subclass describes a 3-stage Administrative Task structure in which the Patient is involved. This has to do with a Patient’s Admission to the hospital, her/his Hospitalization period and his/her possible intra- or inter-hospital Transfer. The third Subclass refers to the Interviews that the Patient may need to complete throughout the whole course of the Disease. These Interviews can either have the form of Questionnaires containing several specific Questions or they could be executed through a Chatbot.

Finally, the Data entity, shown below, represents different data collected/aggregated / in situ / in batch / open data etc. from multiple phases of a disease/pandemic management lifecycle. They are produced as a result of tasks and activities in the addressed domain of pandemics/disease outbreaks and are organized in datasets described by appropriate metadata. For the needs of COVID-X and based on the performed analysis, they have been categorized into 1) Medical and 2) Statistical Data. The 1st Subclass is divided in 1) Device-referring to the Characteristics or Specs of the Device used in monitoring a Patient, 2) History -referring to the Medical History of the Patient (neurologicalDiseases, renalDiseases, dataProvenance, allergies, bloodType, asthma etc.), 3) Lab -referring to the laboratory tests conducted for a Patient and containing ID, result, units, valMin and valMax, in order to allow data transformation to achieve homogenization of the results, 4) Monitoring – referring to all parameters relevant to the Monitoring of a Patient, that are Activity Monitoring (stepCounts, distanceWalkRun, etc.), Rehabilitation, Signs of the Disease (SpO2, respirationEvaluation, restingHeartRate, BMI etc.) and Symptoms (diarrhea, dizziness, jointPain, myalgia, nasalCongestion, rhinorrhea, smellLoss, soreThroat, tasteLoss etc.) and 5) Note -referring to Notes kept in free text regarding a Patient’s situation. The 2nd Subclass, that of Statistical Data, refers to the Open-Source Datasets that are ingested in the COVID-X Sandbox, that contain either Reports (i.e., Demographic Data) or Medical Images (CT scans, X-rays, etc.). From the thorough analysis of all available datasets variables, a number of them have been singled out for describing the same metric but named in different ways, e.g., restHeartRate / restingHeartrate, temp / temperature / body_temperature, respEval / respiration_evaluation, SpO2 / oxygenSaturation, etc.). Harmonization has thus been undertaken at the level of description metadata names to allow for a unified way of describing the respective metrics and further enhance interoperable access.
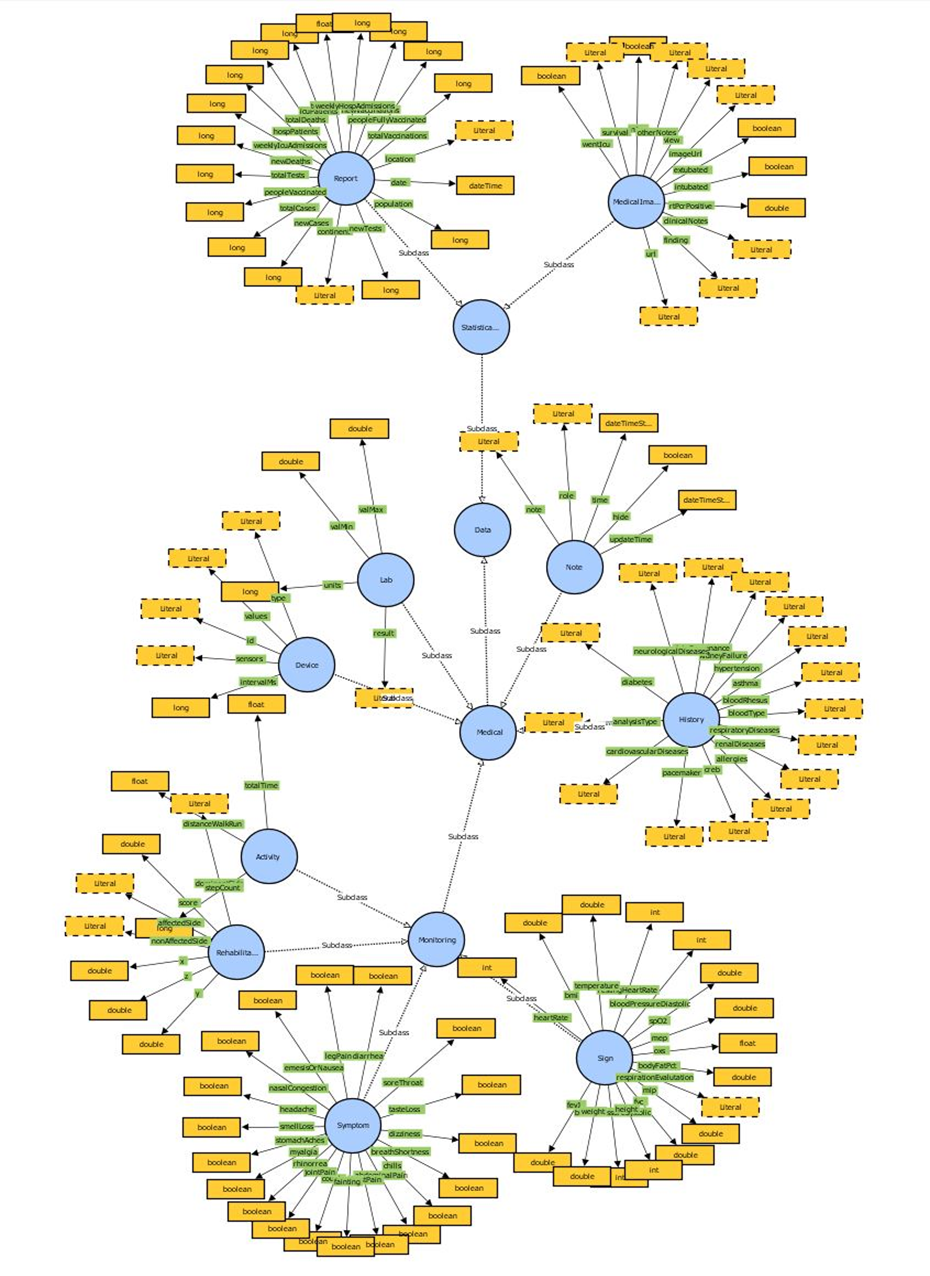
A summary view of the unified Data Model of COVID-X with its lightweight ontology is shown below. The COVID-X Data Model has been defined in its initial version in D2.1 and an updated graphical presentation of the changes introduced after gathering the description needs of Open Call clinical partners/solution providers has been added in an Annex in D2.3.

COVID-X SEMANTIC DATA MODEL – Full ontology
COVID-X Sandbox Services powered by the Unified Data Model
Unified Data Access
The metadata of the aggregated data, harmonized at the description level by the Unified Data Management services of the COVID-X Sandbox, in compliance to the Semantic Data Model, and, when possible, the original data (e.g. in case of open data) are stored in the data storage and catalogue of the Sandbox, and indexed accordingly to be searchable. Each index includes a data schema (index mapping) containing all the different variables/ features related to its context. Proper endpoints (APIs) are established to provide seamless and interoperable access to these data, though querying their metadata, by consuming services (agnostic to the data schemas/formats of the originally ingested data/metadata) – the original data sets may reside at different data centres.
In this way, the unified data access services of the Sandbox enable the interconnection of different/heterogeneous data sources and make them available for other consuming data-driven applications and services such as data analytics and AI services, information visualization, data sharing, etc. in a seamless manner.
Federated Learning
FL is a data driven innovative technique capable of deploying machine learning models in distributed data infrastructures where data is stored. In its architecture, several clients interact directly with data. One server is responsible for requesting information from the clients and combining it to advance in the learning process. All those interactions occur remotely and the client-server communications just involve sending the results of each individual training step produced in the clients to the servers and transferring from the server to the clients the new state of the model from which it starts the next training step. FL moves the computation to the data, and not the opposite. Hence it is essential in projects related to both data and health due to the obligations defined in the data protection policies. Conceptual architecture of the federated learning service is shown below.

The Unified Data Model and the Unified Data Access services of the COVID-X Sandbox benefit the Federated Learning services during the processes of discovering and accessing in a unified and seamless way the relevant data for the specific federated learning and training processing needs across different nodes of the distributed data infrastructure, by querying the unified data catalogue using the structure and semantics of the Unified Data Model.




